
[read this post on Mr. Fox SQL blog]
Recently I have been using Azure DocumentDB (aka CosmosDB) to validate several business use cases for a variety of application purposes.
For those SQL DBA’s and others who are new to Azure CosmosDB, its a recent entrant to the NoSQL document database world, and as its a PaaS document database cloud service it has the agility, scalability and availability of the Azure Cloud.
Being a schema-less Azure PaaS “document database” for my use case I wanted to verify…
- basic costing and performance levels
- methods to create valid JSON documents from SQL Server
- methods to load JSON documents into Azure CosmosDB
- performing basic like-for-like document query comparisons with SQL Server
Some homework reading for those interested…
- For those wanting to know more about NoSQL itself then you seriously just cannot go past the great Wiki article – https://en.wikipedia.org/wiki/NoSQL
- For those wanting to be aware of some Azure CosmosDB use cases then this is a good start – https://azure.microsoft.com/en-us/documentation/articles/documentdb-use-cases/
- For those wanting a good solid background on Azure CosmosDB see this great article – https://www.simple-talk.com/cloud/cloud-data/microsoft-azure-documentdb/
- For the official Microsoft documentation on Azure CosmosDB see this link – https://azure.microsoft.com/en-us/services/documentdb/
- For those wanting to see how SQL and NoSQL data sets can be linked together via leveraging a SQL Server Linked Server, then see my other post here – https://mrfoxsql.wordpress.com/2017/09/26/query-azure-cosmosdb-from-a-sql-server-linked-server/
22 May 2017 [EDIT]
As hinted above, Microsoft have just recently added significant new functionality and also formally renamed Azure DocumentDB as Azure CosmosDB – a major evolution of the NoSQL database engine. The details on the renamed service is here – https://azure.microsoft.com/en-au/blog/dear-documentdb-customers-welcome-to-azure-cosmos-db/
And so… let get into the belly of Azure DocumentDB CosmosDB!
Costing and Performance Levels
An Azure CosmosDB Account is essentially just a container into which you create one or more Databases. Databases, like Accounts, are also just containers into which you create one or more Collections. Collections are where you place your JSON Documents (ie your actual data), and also stores application logic like Stored Procedures, Triggers and Functions (all of which are written in JavaScript). See here if you are interested to read more on DocumentDB programming – https://azure.microsoft.com/en-us/documentation/articles/documentdb-programming/
From a CosmosDB perspective its the Collections that actually determine your cost and performance. You have 2 options…
- You can choose one of the predefined performance levels (S1, S2, S3) each of which allow 10GB document storage.
- OR… you can set your own performance and storage level – and pay accordingly!
The set performance levels allow you to drive a certain amount of throughput per second in your Collection calculated as “RU‘s”. Every time you work with JSON documents in Azure DocumentDB, whether it be loading (inserting), updating (replacing) or selecting (querying), then it is calculated as “RU’s” or Request Units.
During the time you have your CosmosDB collection stored in Azure then whether you use zero RUs per second or your Collections maximum RU per second allocation (say 2500 RUs per second for an S3) then you pay that same amount. So pricing wise its about inline with how Azure SQL Database is priced.
If you push RU throughput to your Collection that exceeds your RU allocation then you will get errors on your client along the lines of “Message: {“Errors”:[“Request rate is large”]}“. DocumentDB performance itself wont degrade or be throttled as you get close to your RU limit so your application needs to handle such errors in case you exceed it.
How do you work out what CosmosDB will cost?
Well, 1 RU corresponds to a GET of a 1KB document. You then need to know the specifics of your workload such as number of documents, avg document size, how the documents are accessed (query patterns), and how often documents are updated.
I suggest loading your data and running your standard queries in the Azure Portal (see below) to see what RU’s your workload generates, and use that in your calculations.
So in my situation I priced up my requirements as follows;
- Approx 20K documents, with each document on average about 3KB. Total data size of approx 40MB
- Approx 85 concurrent SIMPLE queries/sec on the Document Collection. A typical query returning all the orders/details for a specific customer (id). Each query uses approx 3 RU’s therefore we need approx 260 RU / Sec.
- Approx 20 concurrent COMPLEX queries/sec on the Document Collection. A typical query returning all the orders/details for high value orders. Each query uses approx 48 RU’s therefore we need approx 960 RU / Sec
- (In my benchmarking I wasn’t concerned with updates so didn’t calculate this)
TOTAL RU’s / SEC = 1220
Therefore I need an S3 instance (2500 RU’s), or a custom collection serving min 1300 RU’s
Long short, you need to work it out yourself! See this article on the process to do it – https://azure.microsoft.com/en-us/documentation/articles/documentdb-request-units/
2016-07-01 [EDIT]
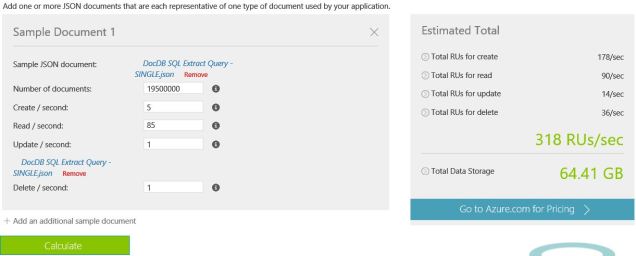
As of about a week ago Microsoft released an awesome sizing estimation tool. All you need is a sample JSON document and some guesstimates of how you’d query the database and it will provide you an RU size and storage size!
https://www.documentdb.com/capacityplanner
Creating JSON Documents from SQL Server
Azure CosmosDB stores JSON documents, which means that any data you try to put into it needs to be a valid document. Additionally you need to ensure that the JSON document you create models the business purpose that you need to store for your data queries, while minimising document updates in the future for changes to the underlying data.
How you model your documents will have a direct impact on your database usability, costs and query performance. I wont go into document modelling in this blog, however if you want to know more then this is an excellent reference – https://azure.microsoft.com/en-us/documentation/articles/documentdb-modeling-data/
If you don’t have any JSON data to test Azure CosmosDB, then you can generate some using SQL Server (below). If you already have some sample JSON data then you can skip this section if you want!
For our purposes, I just want to get some valid data out of SQL Server into a decent JSON document structure so I can load and query it. Luckily SQL Server 2016 can natively talk JSON! Bingo!
This script runs on the AdventureWorks2016 sample database and returns about 10K rows containing 19119 JSON documents about Customer Orders.
You can see some embedded subqueries in the SQL code – this is required if you want to get repeating JSON blocks in your JSON document. This is a great article that spells out some nice methods to get the right JSON structure for child rows – https://blogs.msdn.microsoft.com/sqlserverstorageengine/2015/10/09/returning-child-rows-formatted-as-json-in-sql-server-queries/
SELECT cast(c.CustomerID as varchar(10)) AS id, p.FirstName AS [Name.First], p.MiddleName AS [Name.Middle], p.LastName AS [Name.Last], ( select cast(soh.SalesOrderID as varchar(10)) AS [OrderID], convert(varchar(10), soh.OrderDate, 121) AS [OrderDate], soh.SalesOrderNumber AS [OrderNumber], soh.PurchaseOrderNumber AS [PurchaseOrderNumber], soh.TotalDue AS [Amount], ( select cast(sod.SalesOrderDetailID as varchar(10)) AS [SalesOrderDetailID], sod.OrderQty AS [OrderQty], sod.UnitPrice AS [UnitPrice], sod.LineTotal AS [LineTotal], REPLACE(REPLACE(REPLACE(pr.Name, '''', ''), '/', ' '), '"', '') AS [ProductName] from [Sales].[SalesOrderDetail] as sod inner join [Production].[Product] pr on sod.ProductID = pr.ProductID where soh.SalesOrderID = sod.SalesOrderID order by sod.SalesOrderDetailID FOR JSON PATH ) as [OrderDetail] from [Sales].[SalesOrderHeader] as soh where soh.CustomerID = c.CustomerID order by soh.SalesOrderID FOR JSON PATH ) as [Orders] FROM [Sales].[Customer] c inner join [Person].[Person] p on c.PersonID = p.BusinessEntityID order by c.CustomerID FOR JSON PATH
Running the query on SQL Server 2016 will output a JSON document structure that looks something like this…
[
{
"id": "15447",
"Name": {
"First": "Regina",
"Last": "Madan"
},
"Orders": [
{
"OrderID": "58744",
"OrderDate": "2013-10-27",
"OrderNumber": "SO58744",
"Amount": 27.614,
"OrderDetail": [
{
"SalesOrderDetailID": "67055",
"OrderQty": 1,
"UnitPrice": 24.99,
"LineTotal": 24.99,
"ProductName": "LL Mountain Tire"
}
]
}
]
}
]
How can you tell if your JSON is valid?
- Because SQL Server created the JSON its going to be valid, but if you ever wanted to validate it you can use the new SQL Server 2016 “ISJSON” function – see here https://msdn.microsoft.com/en-us/library/dn921896.aspx
- OR… my personal favourite in this online JSON viewer/validator/formatter – becasue it has multiple functions and does a beautiful job – http://codebeautify.org/jsonviewer
The Pain of Multiple JSON Rows in SSMS Output
When exporting JSON data to the SSMS GUI from SQL Server there is a little quirk you need to be aware of. If the JSON output in SSMS returns over multiple rows then you will find that its valid but CosmosDB wont like it because it cannot parse it. So if exporting data in SSMS it means you need to get all the JSON output rows onto a single line of text.
SSMS JSON EXPORT – if you have LESS than 65K characters — then you can do this by assigning the JSON to a VARCHAR(MAX) variable like below… but any more than 65K and it will wrap lines in SSMS.
DECLARE @JSONText NVARCHAR(MAX) SET @JSONText = ( "MySQLtoJSONQueryHere" ) select ISJSON(@JSONText) SELECT @JSONText
SSMS JSON EXPORT – if you have MORE than 65K characters — then you can do it by running a PowerShell that extracts the JSON file. Quick and dirty, but it works!
$DBServer = "MySQLServer"
$DBName = "MyDatabase"
$outputfile = "MyOutputPathAndFile"
$Query = "MySQLtoJSONQueryHere"
$cn = new-object System.Data.SqlClient.SqlConnection("Data Source=$DBServer;Integrated Security=SSPI;Initial Catalog=$DBName")
$cn.open()
$cmd = new-object "System.Data.SqlClient.SqlCommand" ($Query , $cn)
$reader = $cmd.ExecuteReader()
while ($reader.Read())
{
for ($i = 0; $i -lt $Reader.FieldCount; $i++)
{
$FullString = $FullString + $Reader.GetValue($i)
}
}
$FullString | Out-File $outputfile
Loading JSON Documents into Azure CosmosDB
Once you have your valid JSON files, there are a number of methods to get that data into an Azure CosmosDB…
- The Azure Portal. In the Document Explorer section of your Collection you can Upload documents. There is a limit of 100 documents you can load at a time. Good for once off, not so good for a repeated method
- Programatically. Naturally this would be your application logic itself – so maybe not good for bulk loads unless thats what you wrote your application to do! Here’s a guide to the required code against CosmosDB – http://social.technet.microsoft.com/wiki/contents/articles/27047.creating-and-querying-microsoft-azure-documentdb.aspx
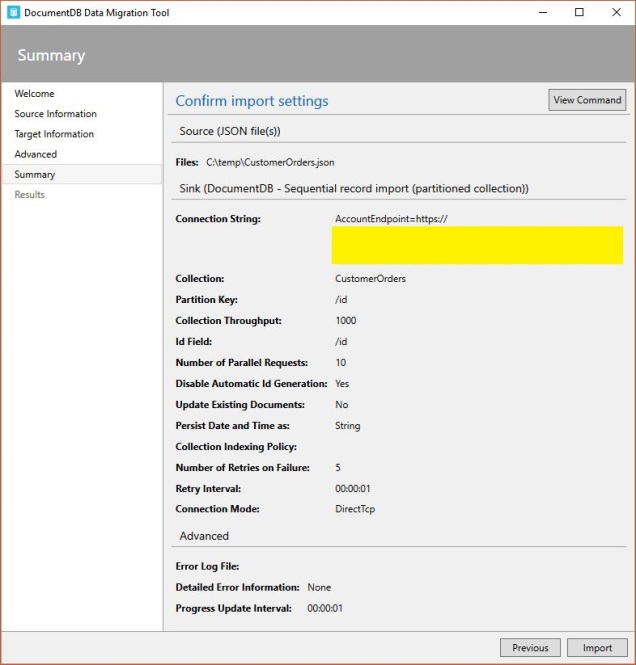
- CosmosDB Data Migration Tool. This is the one we’ll use today. For bulk loading this is really nice as its a wizard driven GUI which can also be executed by command line – which means you can create scheduled data loading jobs. See this article – https://azure.microsoft.com/en-us/documentation/articles/documentdb-import-data/
The CosmosDB Data Migration Tool allows loading from lots of different source systems directly into Azure CosmosDB. The main reasons I like it…
- Its very simple to use, but can also do some complex stuff
- It offers both sequential and batch record loading. Batch is faster but has fewer options.
- Performance wise its pretty quick – you can also increase the number of parallel requests (but beware if you hit your RU limit some document loads can fail with {“Errors”:[“Request rate is large”]})
- You can immediately partition your documents by an id within the document (I wont go into the benefits of partitioning here, maybe later, but if interested here’s the partitioning feature here – https://azure.microsoft.com/en-us/documentation/articles/documentdb-partition-data/)
- Where the document id matches, it can update those existing documents in place
- You can setup your document indexes within the tool
- Any import you create with the tool can be saved as a command line activity
I setup an Azure CosmosDB Collection as per below and I ran several different load tests with the following performance results.
Load Particulars…
- Target Database: Single Partition Azure CosmosDB Collection, 1000 RU’s, S2
- Source File: 39MB JSON data file containing 19119 documents (each document is approx 3KB)
Load Performance…
| Load Type | Requests/Sec | Time (mm:ss) | Failed Documents |
| Sequential | 10 | 23:05 | 0 |
| Bulk | 50 | 07:21 | 0 |
| Sequential | 100 | 08:38 | 257 |
| Sequential | 1000 | 08:08 | 311 |
NOTE that the Data Migration Tool can also extract data directly from SQL Server and into CosmosDB, but it didn’t correctly extract multiple levels of repeating child data so I didn’t benchmark it. Give it a try yourself as your mileage may vary.
Querying JSON Documents from Azure CosmosDB
Ok so its about time we look at ways to get data out! CosmosDB is NOT a big data store – so no point here storing data unless you are going to actually use it!
The Azure DocumentDB query language is very similar to that of SQL Server T-SQL and so for the SQL DBA’s out there you will note some close similarities – and some stuff that just does not fit well in your relational headspace.
- The CosmosDB Query Reference which has some great examples is here – https://azure.microsoft.com/en-us/documentation/articles/documentdb-sql-query/
- However – if you just want to have a try of the Query Language without setting anything up then this is a nice online demo database you can use live – https://www.documentdb.com/sql/demo
To run queries you have a few options;
- The Azure Portal. In the Query Explorer section of your Collection you can type in and run queries against the documents in your collection. It will output the results along with how many RU’s of your maximum allocation that query used.
- Programatically. Naturally this would be your application logic itself!
- Azure CosmosDB Studio. This is not a Microsoft tool – however I really like this tool as you can browse your collections and perform many document related functions. It also shows the query RU’s and elapsed time (the Azure Portal does not show time). The code is here on GitHub so you can download and compile it – https://github.com/mingaliu/DocumentDBStudio
- Visual Studio (2013/2015). Nope, unfortunately Visual Studio Azure Cloud Explorer currently does not support running queries against CosmosDB, hopefully this comes soon!
Lets do some basic query comparisons with SQL Server!
NOTE that I cleared the SQL Server buffer cache etc before each SQL query run to get a baseline performance.
Return Single Document by ID (First Document in Collection)
SQL Server 2016
SELECT * FROM [Sales].[Customer] c inner join [Person].[Person] p on c.PersonID = p.BusinessEntityID inner join [Sales].[SalesOrderHeader] as soh on soh.CustomerID = c.CustomerID inner join [Sales].[SalesOrderDetail] as sod on soh.SalesOrderID = sod.SalesOrderID inner join [Production].[Product] pr on sod.ProductID = pr.ProductID WHERE c.CustomerID = 11000
ELAPSED TIME (MS) = 102
Azure CosmosDB
SELECT * FROM CustomerOrders c WHERE c.id = "11000"
ELAPSED TIME (MS) = 72 (RU = 3)
Return Single Document by ID (Last Document in Collection / Last Row in Database)
SQL Server 2016
SELECT * FROM [Sales].[Customer] c inner join [Person].[Person] p on c.PersonID = p.BusinessEntityID inner join [Sales].[SalesOrderHeader] as soh on soh.CustomerID = c.CustomerID inner join [Sales].[SalesOrderDetail] as sod on soh.SalesOrderID = sod.SalesOrderID inner join [Production].[Product] pr on sod.ProductID = pr.ProductID WHERE c.CustomerID = 18759
ELAPSED TIME (MS) = 54
Azure CosmosDB
SELECT * FROM CustomerOrders c WHERE c.id = "30118"
ELAPSED TIME (MS) = 783 (RU = 9)
Return Single Document By Last Name Order by First Name
SQL Server 2016
SELECT * FROM [Sales].[Customer] c inner join [Person].[Person] p on c.PersonID = p.BusinessEntityID inner join [Sales].[SalesOrderHeader] as soh on soh.CustomerID = c.CustomerID inner join [Sales].[SalesOrderDetail] as sod on soh.SalesOrderID = sod.SalesOrderID inner join [Production].[Product] pr on sod.ProductID = pr.ProductID WHERE p.LastName = 'Yang' ORDER BY p.FirstName
ELAPSED TIME (MS) = 765
Azure CosmosDB
SELECT * FROM CustomerOrders c WHERE c.Name.Last="Yang" ORDER BY c.Name.First
ELAPSED TIME (MS) = 432 (RU = 75)
Return Top 10 Customer Orders
SQL Server 2016
SELECT TOP 10 c.CustomerID AS id, soh.SalesOrderID AS [OrderID], soh.TotalDue FROM [Sales].[Customer] c inner join [Sales].[SalesOrderHeader] as soh on soh.CustomerID = c.CustomerID inner join [Sales].[SalesOrderDetail] as sod on soh.SalesOrderID = sod.SalesOrderID
ELAPSED TIME (MS) = 155
Azure CosmosDB
SELECT TOP 10 c.id, o.OrderID, o.Amount FROM CustomerOrders AS c JOIN o IN c.Orders
ELAPSED TIME (MS) = 72 (RU = 5)
Return All Orders Where Amount > 50000
SQL Server 2016
SELECT soh.SalesOrderID AS [OrderID], soh.TotalDue AS [Amount] FROM [Sales].[SalesOrderHeader] as soh WHERE soh.TotalDue > 50000
ELAPSED TIME (MS) = 34
Azure CosmosDB
SELECT c.OrderID, c.Amount FROM CustomerOrders co JOIN c IN co.Orders WHERE c.Amount > 50000
ELAPSED TIME (MS) = 276 (RU = 310)
Return All Customers and Orders Where Quantity Between 20 and 25
SQL Server 2016
SELECT c.CustomerID AS id, soh.SalesOrderID AS [OrderID], soh.OrderDate AS [OrderDate], soh.TotalDue AS [Amount], sod.OrderQty AS [OrderQty] FROM [Sales].[Customer] c inner join [Sales].[SalesOrderHeader] as soh on soh.CustomerID = c.CustomerID inner join [Sales].[SalesOrderDetail] as sod on soh.SalesOrderID = sod.SalesOrderID WHERE sod.OrderQty between 20 and 25
ELAPSED TIME (MS) = 72
Azure CosmosDB
SELECT c.id, o.OrderID, o.Amount, o.OrderDate, od.OrderQty FROM CustomerOrders AS c JOIN o IN c.Orders JOIN od IN o.OrderDetail WHERE od.OrderQty between 20 and 25
ELAPSED TIME (MS) = 366 (RU = 121)
Return Just the First Order for Each Customer Where Amount > 5000 and Quantity > 20 and Order By the Customer ID
SQL Server 2016
with CTE as ( SELECT SalesOrderID AS [OrderID], OrderDate AS [OrderDate], TotalDue AS [Amount], ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) as RN FROM [Sales].[SalesOrderHeader] WHERE TotalDue > 5000 ) SELECT cte.[OrderID], cte.[OrderDate], cte.[Amount], sod.OrderQty FROM CTE inner join [Sales].[SalesOrderDetail] as sod on cte.[OrderID] = sod.SalesOrderID WHERE cte.RN = 1 AND sod.OrderQty > 20 order by 1
ELAPSED TIME (MS) = 95
Azure CosmosDB
SELECT c.OrderID, c.OrderNumber, c.Amount, od.OrderQty FROM CustomerOrders.Orders[0] AS c JOIN od IN c.OrderDetail WHERE od.OrderQty > 20 AND c.Amount > 5000 ORDER BY c.OrderID
ELAPSED TIME (MS) = 204 (RU = 198)
What’s Missing in the Query Language?
The DocumentDB query language isn’t fully developed (yet!) so there’s some things that it doesn’t do well, and things you cannot do at all.
- ORDER BY. When querying a “single” collection you can use ORDER BY, however if you do an “intra-document join” then ORDER BY will fail with “Order-by over correlated collections is not supported“. So in my case the query to “SELECT TOP 10 Customers ORDER BY Customers.OrderAmount” fails as this query needs to join Customers to its inner level Orders to get the Amount. This will be supported in the future. See this article – https://azure.microsoft.com/en-us/documentation/articles/documentdb-orderby/
- AGGREGATES (GROUP BY, SUM, MAX, MIN, AVG, COUNT). Aggregates were added as a new feature in March 2017 and thus are now supported in DocumentDB. FEATURE COMPLETED [EDIT] – https://feedback.azure.com/forums/263030-documentdb/suggestions/6333963-add-support-for-aggregate-functions-like-count-su?tracking_code=a1888fab24e56b1573622ee33c3e3bb4.
Key Summary
So there you have it – a pretty good start into understanding about Azure CosmosDB – creating JSON from a SQL Query, methods for loading JSON documents and methods for querying JSON documents.
For the SQL DBA’s out there hopefully this has also given you a bit of a peek into the world of Azure, JSON, CosmosDB and NoSQL and demystified what they are for, their use cases and how they work.
NoSQL isn’t going to replace any relational databases in the world any time soon – they clearly serve different use cases – however the new future world of the modern DBA will have a requirement to know, manage and operate not just your cornerstone relational database systems but also many other on-prem, hybrid and cloud data stores such as HDInsight/Hadoop, Data Lake and NoSQL to name a few.
As per usual with all my posts, please test everything yourself as your mileage may vary!
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here


Thanks! Have you tried using the DocumentDB ODBC driver with SSIS? I wish I could use it as a linked server…
LikeLike
Hi Alex. Although not directly related to your question, I blogged here on how you can create a SQL Linked Server using the ODBC Driver. Many of the steps for setting up the ODBC driver (which are still applicable to SSIS) are outlined in this post – https://mrfoxsql.wordpress.com/2017/09/26/query-azure-cosmosdb-from-a-sql-server-linked-server/
LikeLike
Hi Alex – sorry for the delay – no I haven’t tried to connect to CosmosDB using the ODBC driver before. However if you haven’t seen it this is a good article showing how to configure the driver. Given its just a system DSN then setting up a linked server should be reasonably easy (caveat is I havnt done it for Cosmos!)
https://docs.microsoft.com/en-us/azure/cosmos-db/odbc-driver
LikeLike
Is it possible to load JSON documents with different schemas/models on the same collection?
Is it possible to load JSON documents without binding to a model?
LikeLike
Yep definitely possible to do this, nothing stops you putting in a JSON document structured one way or another. In fact this is quite normal if a JOSN document slowly changes over time (ie new properties, new arrays, etc etc).
What do you mean by “binding to a model”? CosmosDB is totally schemaless, and there are no models enforced.
Hope that helps!
LikeLiked by 1 person
Thank you. I thought I had to instantiate the JSON string on a class object because of the sample code:
public static async Task CreateItemAsync(T item)
{
return await client.CreateDocumentAsync(UriFactory.CreateDocumentCollectionUri(DatabaseId, CollectionId), item);
}
I was led to think that T as a well defined class and, as so, wouldn’t change when the code was in production. My mistake and thanks again.
LikeLike
No problems. In a lot of my use cases I stream data directly into CosmosDB via Stream Analytics or an Azure Function (triggering from an event landing into Event Hub). The most recent had documents with massive variation (ie missing hundreds of attributes, various arrays etc) and still worked well! The onus is mostly on the reader to get their “schema on read” structures correct.
LikeLiked by 1 person
After your comment I tried it myselft and it worked.
Thanks again.
LikeLike