
[read this post on Mr. Fox SQL blog]
For the longest time data science was often performed in silos, using large machines with copies of production data. This process was not easily repeatable, explainable or scalable and often introduced business and security risk. With modern enterprises now adopting a DevOps engineering culture across their applications stack, no longer can machine learning development practises operate in isolation from the rest of the development teams.
Thankfully – earlier this year Microsoft GA’d a new service called Azure Machine Learning Services which provides data scientists and DevOps engineers a central place in Azure to create order out of what can be a complicated process.
This blog post outlines the DevOps process when applied to ML. I have also presented on this topic several times, see My Presentation section here – Azure ML DevOps Workflow (wordpress.com)
So what exactly is DevOps?
DevOps is a software engineering practice that aims at unifying software development and software operation. The main characteristic of the DevOps movement is to strongly advocate automation and monitoring at all steps of software construction, from integration, testing, releasing to deployment and management.
PRIMARY GOAL OF DEVOPS: Enable faster time to market, lower failure rate, shortened lead times, and automated compliance with release consistency.
At times I have heard (incorrectly) people interchange or swap terms like DevOps and Agile. So there is no confusion, lets try boil this down to one simple graphic…

But, does Agile make sense for ML projects?
Well now, here’s an interesting footnote for Agile and Machine Learning development!
The intent of Agile is to break application development timeframes into a series of discrete “sprints” comprising (typically) of 1, 2 or 3 weeks. Each sprint delivers a unit of the whole application, till eventually the whole application is delivered, tested and completed.
Most ML development projects often don’t roll this way, and rarely follow a smooth cycle. Much of the effort has relatively unknown timeframes with sometimes relatively unknown outcomes. Its not uncommon for several weeks to be spent investigating, profiling, cleaning and featurising datasets only to discover it… (a) doesn’t contain enough goodness to justify the subsequent ML modelling effort, or that… (b) your model prediction accuracy, error amounts or some other critical metric is just so damn lousy you need shelve the whole idea. Yeah, it happens.
Thus, some data science projects don’t fit well with an Agile methodology. However given above that [Agile <> DevOps] then that does not exclude modelling artefacts like training code, trained models, validation scripts, score scripts, etc from being managed via DevOps build and release pipelines.
So yes, there’s still benefits from DevOps for data scientists everywhere!
So is there really a problem? What is this trying to solve?
In talking with various development teams, customers and DevOps engineers, a lot of the potential problems of meshing ML development into an enterprise DevOps process can be boiled down to a few different areas this aims to address…
- ML stack might be different from rest of the application stack
- Testing accuracy of ML model
- ML code is not always version controlled
- Hard to reproduce models (ie explainability)
- Need to re-write featurizing + scoring code into different languages
- Hard to track breaking changes
- Difficult to monitor models & determine when to retrain
So DevOps helps with this, right? Right?
Well er, some of them yes, but not all.
DevOps itself wont solve the problems. However when DevOps is integrated with Azure ML Services (see below) it will enable methods by which a consistent, repeatable and reliable process can be applied (automatically in many cases) to ML model build, test and release stages which subsequently supports the data scientist with tooling, logs, and information to perform those activities.
What is the Azure Machine Learning Service?
The Azure Machine Learning service provides a cloud-based environment you can use to prep data, train, test, deploy, manage, and track machine learning models. You can start training on your local machine and then scale out to on-demand compute in the cloud. The AML service fully supports open-source technologies such as PyTorch, TensorFlow, and scikit-learn and can be used for any kind of machine learning, from classical ML to deep learning, supervised and unsupervised learning.
https://azure.microsoft.com/en-us/services/machine-learning-service/
The Azure ML Service workspace (deployed in an Azure Subscription) exposes a number of helpful cloud based sub-services to data scientists and DevOps engineers to track experiments, build training runs, wrap models into docker container images and release containers as consumable web services.
The ML services exposed in the workspace include…
- Automated Machine Learning (AutoML)
- ML model training experiment logging and tracking
- Managing ML model training runs to burst onto on-demand scalable training compute
- Storing/versioning trained ML model artefacts
- Storing/versioning Docker container images with the trained ML model artefacts
- Managing deployments of ML model Docker containers for real-time web scoring
- Storage and Application Insights services to monitor ML model usage
But I think the real magic sauce that makes DevOps and ML integrate so nicely with the Azure ML Service is the Azure Machine Learning Python SDK. Importing the SDK into your python code, or leveraging the SDK CLI in DevOps pipelines, enables data scientists or engineers to “connect” into the cloud services to access the ML management tooling and features.
The cool thing about this SDK as its totally independent of any development tooling, so that means you can use it in your preferred python development IDE, however exotic that is. So if you like VS Code, or PyCharm, or Jupyter, or Databricks, or Zetor, etc, then no problems, go for it. (yeah OK, I made that last tool up!)
The Azure ML Service SDK documentation is here – https://docs.microsoft.com/en-au/python/api/overview/azure/ml/intro
Code Management / Model Flow (example)
Below is an outline of the data flows and data storage, ML model development IDE and training compute layers, batch scoring compute layer and finally the ML DevOps processes, including retraining triggers.
Its really, REALLY important to note that this is just an example of how an ML DevOps process can be built, its not the example!
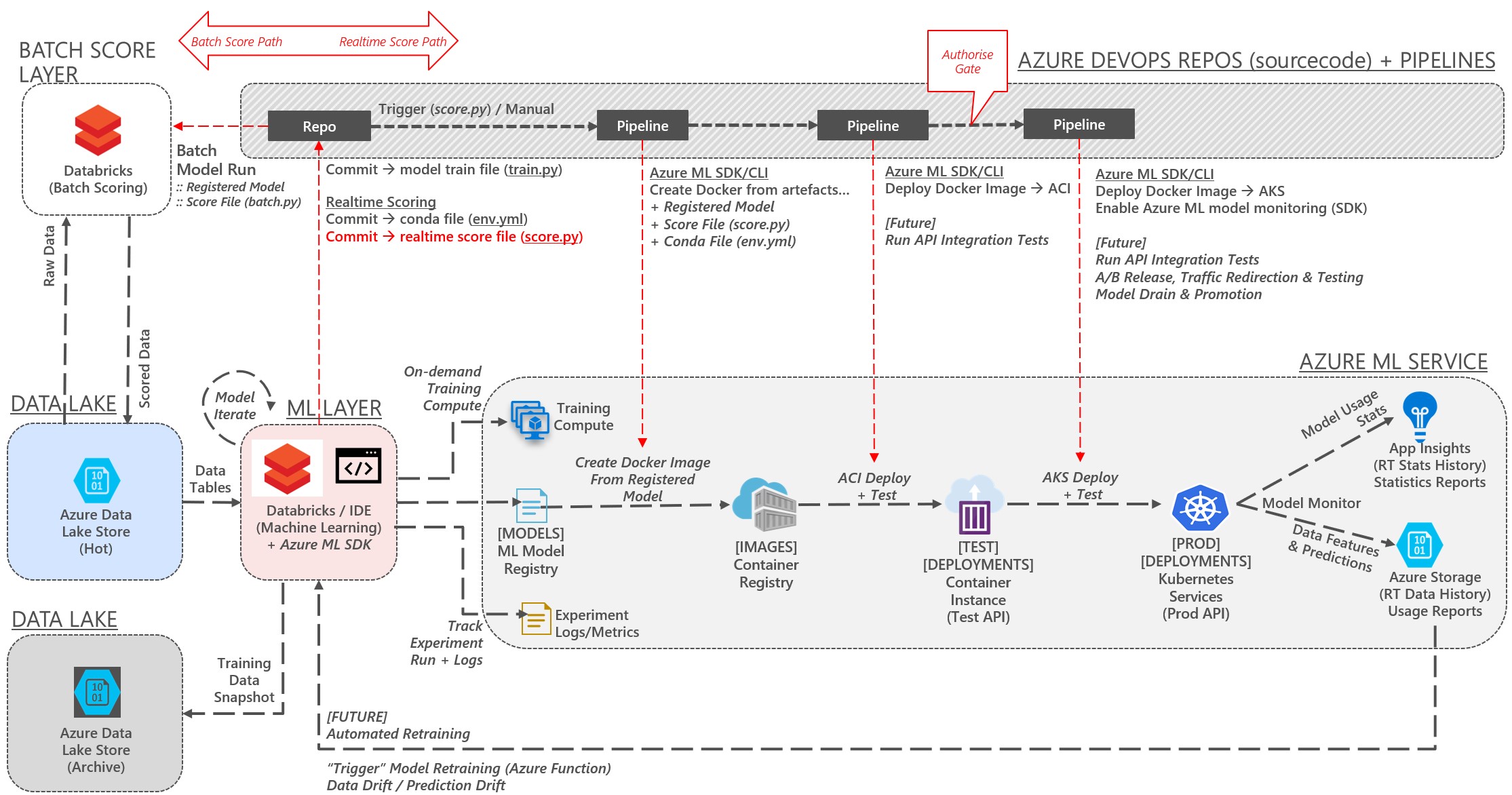
A couple of points that can change on this example flow…
- Its not unreasonable to have different DevOps build and release pipelines for each model. Often the methods of model re/training, cadences, and release can be vastly different per model.
- The DevOps pipelines should be constructed so that they are inline with the business expectations for the model.
- For example – if the business expect there to be an approval gate between model testing and release then that needs to be built into the DevOps release pipeline.
- Or – if the business expect models to be released via an A/B method then that needs to be built into the release pipeline, and so on.
- Model retraining could be triggered via any number of actions, such as a simple timer schedule, monitoring the model prediction accuracy falling below a set threshold, or some aggregate combination of features exceeding some set bounds.
Regardless of the trigger method, the trigger action is usually to kick off a new automated model re/training run using the latest data in the “data lake” and, if the trained model passes validation tests, releasing it to production. - In my example above, the model training occurs outside the DevOps build pipeline, however its not uncommon for that training to be executed from within the build pipeline itself. So based on some automated or defined schedule, or trigger, the DevOps build process kicks off and…
- pulls the train.py code from a git repo,
- pulls the latest trained model version from the Azure ML Service model repository
- trains the ML model using on-demand training compute defined in the Azure ML service workspace based on the latest data available in the “data lake”,
- tests and compares predictive scores of the new model with that of the old model already running in production
- if better, registers the updated trained model back into the Azure ML Service model repository as the latest version.
- to support “explainability” (see below) also keeps a snapshot copy of the data used to train the model
- “Explainability” and “Reproducibility” for models is fast becoming the norm, especially for models with predictive scoring that affects peoples lives. To help support this its often a combination of…
- continued model code management and versioning,
- trained model artefacts management and versioning,
- automated DevOps release processes (ie no click ops)
- training data retention and tagging (ie. as above – snapshotting an exact copy of the entire dataset used to train any one model)
- scoring and prediction data retention (ie model monitoring).
- Lastly, Azure ML also has a number of explainability features built in that can help this process, see here – https://docs.microsoft.com/en-us/azure/machine-learning/service/machine-learning-interpretability-explainability
I’m a Data Scientist, what do I need to do?
So if you wear the hat of a data scientist you might well think this looks hard, or complex, or just yet another thing you need to do. In reality you don’t need to do much at all, the ML DevOps process does not expect a data scientist to be a DevOps engineer, it just expects them to do the right thing by the process and let DevOps magic take care of the rest!
At a basic level, this essentially means…
- commit all python model code to a repo, and ensure all changes to that code are always (always!) managed via that repo
- ensure your code integrates with the Azure ML Service via the SDK so you can leverage experiment tracking/logging features, etc. This is optional, but there are clear benefits to explainability in doing this.
- never manually release or push your code, or any artefacts created by your code (ie such as a trained model) to any environment other than your local playpen. Let the DevOps process always build and release your code and artefacts to shared environments in a controlled way.
So yep – that’s about it!
I’m a DevOps Engineer, what do I need to do?
So if you wear the hat of a DevOps Engineer you might well think this looks hard, or complex, or just yet another thing you need to do. In reality you are correct, it will be more pipeline work you need to do!
At a basic level, this essentially means that each and every build or release pipeline will likely need to be customised in some way so it meets the production release needs of a particular business process.
- Some models might need authorisation before release,
- others may need an A/B test approach,
- others again might have an edge or on-prem deployment, etc.
- All different needs, all different pipelines.
When building pipelines it can be done via either integrating the Azure ML Service Python SDK or the Azure ML Service CLI into the DevOps pipeline activities. Either way – both methods enable the pipelines to access Azure ML Service features such as spinning up on-demand training compute, containerising ML models into Docker Images, deploying docker images onto ACI or AKS, enabling model monitoring, and a whole heap more.
Conclusion
Well there you have it, a quick summary of the why’s, how’s, who’s and what’s of implementing your data science model development processes into a modern enterprise DevOps methodology.
As you can imagine with this type of activity, it will depend, a lot, on the purpose and business drivers of the models, and in particular how those models will be consumed or integrated into or by other downstream processes.
So as usual, and as I always so, always give this a try yourself, as your own mileage may vary!
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here

One thought on “Machine Learning + DevOps = ML DevOps (Together at Last)”